
Publications
 |
VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision
|
 |
ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
|
 |
Self-Supervised Object Detection via Generative Image Synthesis
|
 |
Self-Supervised Viewpoint Learning From Image Collections
|
 |
Intrinsic Autoencoders for Joint Deferred Neural Rendering and Intrinsic Image Decomposition
|
 |
iPose: Instance-Aware 6D Pose Estimation of Partly Occluded Objects
|
 |
Bounding Boxes, Segmentations and Object Coordinates: How Important is Recognition for 3D Scene Flow Estimation in Autonomous Driving Scenarios?
|
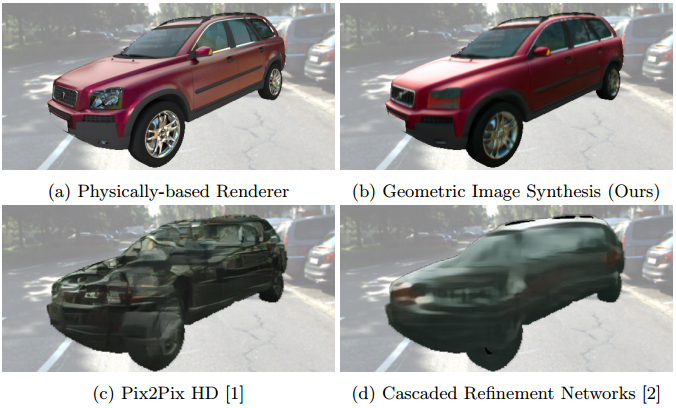 |
Geometric Image Synthesis
|
 |
Augmented Reality Meets Computer Vision : Efficient Data Generation for Urban Driving Scenes
|
| |
Augmented Reality Meets Deep Learning for Car Instance Segmentation in Urban Scenes
|
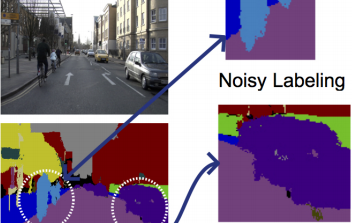 |
Can Ground Truth Label Propagation from Video help Semantic Segmentation?
|
 |
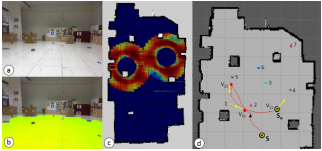
Markov Random Field based Small Obstacle Discovery over Images
|
 |
Guess from Far, Recognize when Near: Searching Floor for Small Objects
|